A Data Mesh from Scratch in Rust — Part 10 — The Server
Finally, we get to the server part. When I started this series, I honestly thought building the storage engine would be really hard and time consuming. I was wrong! The server implementation drove me up the walls.
I also figured out that implementing the bloom filter made it really easy for me when it came to deleting events from the storage engine.
So the primary idea behind the server is that we have three threads:
- One for running the server accepting incoming requests.
- The second for adding these events into the storage engine.
- The third for compacting the
MemTableandSSTables.
Note: I have made a few changes to the library since I wrote the previous articles in the series. Mostly smaller stuff suggested by clippy and like. The one that I think should be mentioned is that SSTable merge now returns a new SSTable for the merged version. This lets me hold pointers to all the storage engine data and iterate over them when required in the server.

The first thing I do is define a wrapper struct that holds my library interface enclosed in a RwLock from the parking_lot crate (supposedly their locks are faster and Reads do not starve Writes). This design allowed me to be able to not fear about introducing deadlock bugs (otherwise, I would have to make sure all locks are attempted in a “stand-alone” fashion).
Once again, nothing spectacular is going on with the methods. They simply wrap around the library API and convert the StorageEngineErrors to anyhow errors.
On the server side, I built a TCP server since I have already built HTTP servers with Rust using actix-web. This time I wanted to work with async threads using tokio. On a related note, Rust’s async environment is really fractured between async_std and tokio. I am using tokio, since it has been around longer and a lot of other async crates — like actix — use tokio. That just saves me the trouble of using things like compat mode and trying to mix and match tokio and async_std getting completely lost in the process.
On the server side, I hold a queue using a Arc<RwLock<VecDeque<Request>>>, which can be easily transformed to a ring buffer (but I don’t see the use case here). I really wanted something like the crossbeam deque here. But unfortunately, that is SPMC (Single Producer Multiple Consumer) whereas I needed a MPSC (Multiple Producer Single Consumer) since there are multiple threads receiving the requests and one processing them. Anyhow, as requests come in to the server, they are added to this deque and the add_event thread is informed through a unbounded channel. The compaction thread is also informed through another unbounded channel. This thread, upon receiving each notification, checks the size of the MemTable against the threshold and performs the compaction is required.
The threads processing incoming requests serve the Read requests in situ. Thus, the processing threads invoke the Read locks when required. The add_event thread invokes the Write lock to get the events on to the storage engine. Thus there is a clean separation of Reads and Writes onto different threads. And since readers do not starve writers, we are confident that most accepted, by the server, events will be written onto the storage engine. The compaction thread invokes the Write lock but only sparingly given the threshold and speed, size of event arrival.
Though I wonder, if we can use a separate cache, to avoid this interplay between locks and speed things up a little more. Another, more complicated, approach might be to use different tables for reads and writes (we might have to accept some delay between writes and the write being available in the read).
Anyway, without further ado, here is what the main thread looks like:

Essentially, this loop accepts each new connection sends it over to a new thread along with the deque, the server and the two unbounded channels.
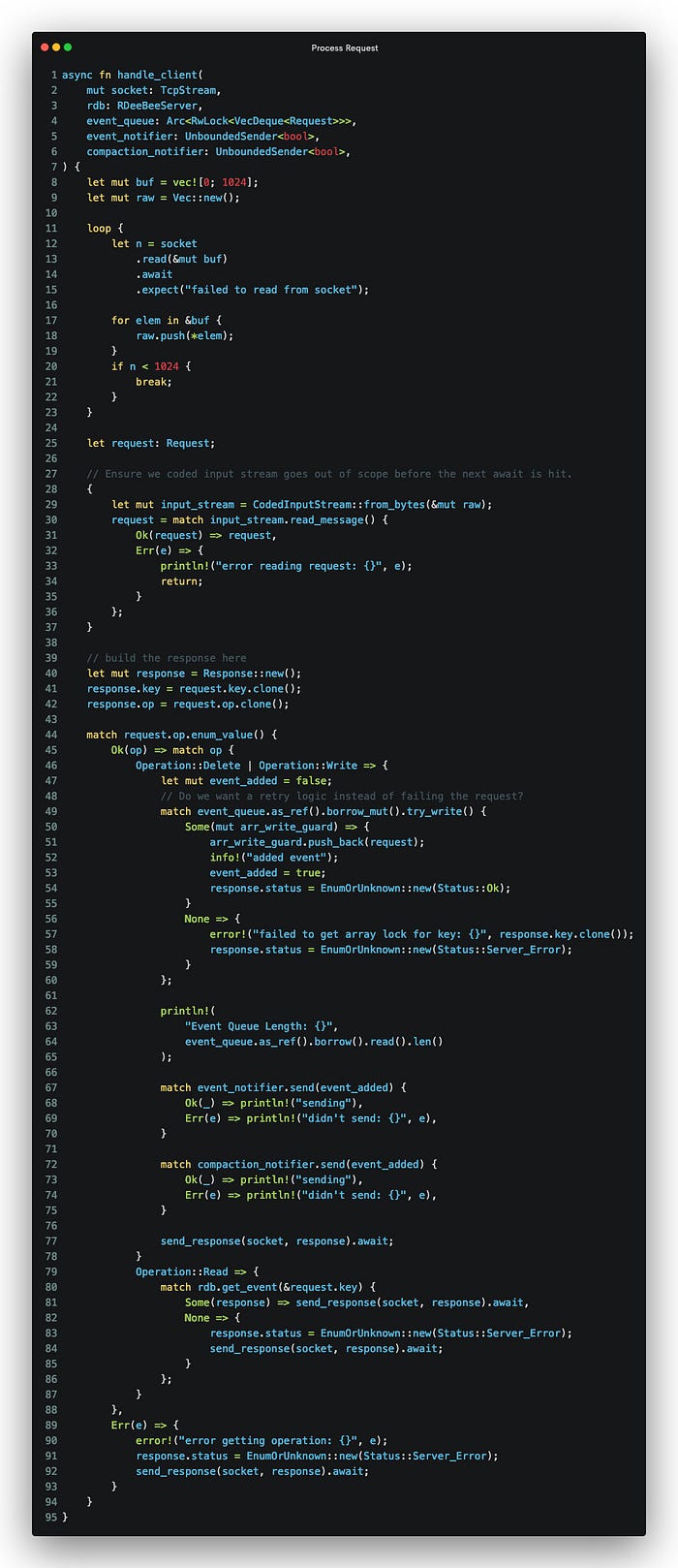
This rather large method processes each request by:
- Getting the entire request body in 1KB chunks.
- Recreating the message from the request.
- It then sends notification of a new event if it was a
WriteorDelete. Otherwise, aReadrequest is served directly. Note that the response of aReadrequest notes the event type of the last request and not the fact that this was aReadrequest. This is different fromWriteandDeleterequests. - It finally updates the
Responsestatus and sends it.
The one thing that really needed a lot of time was sending and receiving the protobufs correctly over the network. There is not a lot of documentation in the crate and I kept getting Incorrect tag errors till I found this test.
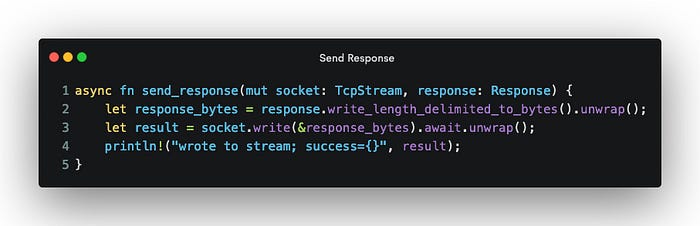
The function sending the response is simple enough.
The add_event thread is also reasonably simple, even if long:
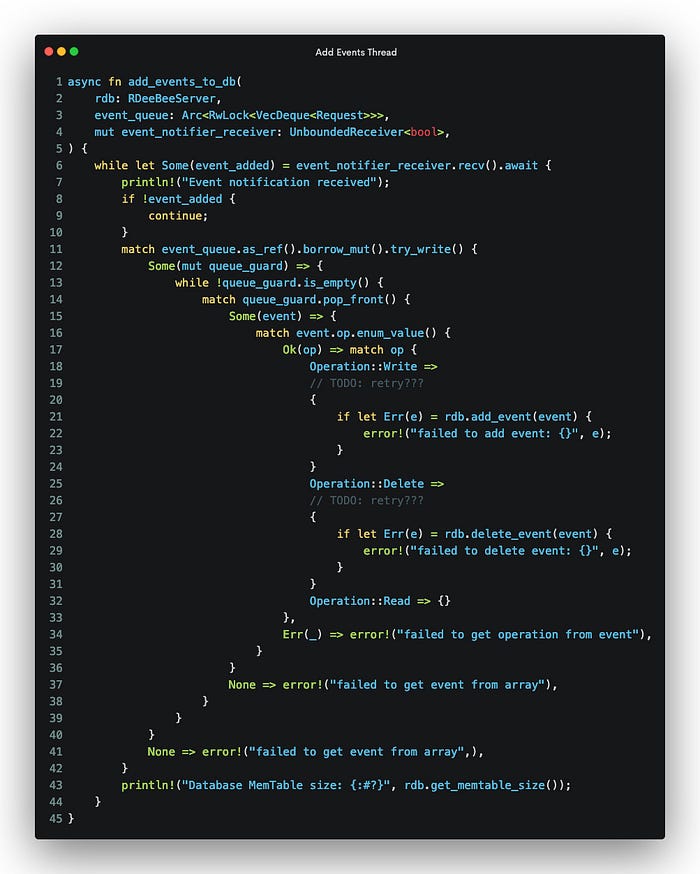
It basically waits around for a notification. Upon receiving that notification it checks whether it is a Write or Delete event (completely ignoring Read since we know there is no notification for Read to this thread) and takes appropriate action.
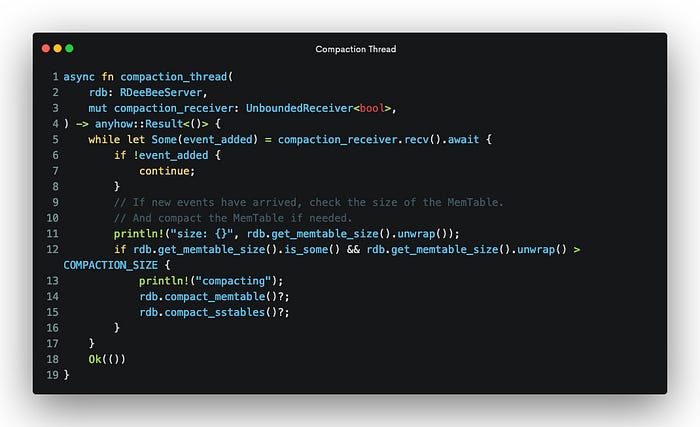
The compaction thread works the same way. As of now, we club MemTable and SSTable compaction but that can easily be separated.
As a final note, I also wanted to use mio here for compaction. The idea was to watch the raw file descriptor for the wal file. As events get added to wal file, the poll notifies the thread and compaction happens. I am adding that code here for completeness and hoping someone will correct it. But I couldn’t get it to work. And after the first couple of days of writing the server, my goal was to get an MVP going, so I dropped the polling idea.

The client is rather straightforward:

And the entire code can be found here.
I have not yet decided what comes next. But most likely it will be the distributed operations.
